
Introduction to etcd
Etcd is a distributed, reliable key-value store. Etcd can be used as a cornerstone service to implement highly available distributed systems such as Kubernetes. It is open source and available from GitHub.
Automated failover, consensus, and etcd
Historically, stores of state, like SQL databases (e.g., MySQL), have provided replication between a single master and one or more replicas, and the means to manually "promote" a replica to master as a mechanism to achieve high availability. The operator decides when to promote and the choice of replica, including:
- The need to automatically monitor and detect failure of the master.
- The need to alert the failure to a human operator.
- Operator analysis to decide on failover need and select a healthy replica.
- Operator action to trigger failover to that specific replica.
As scale increased, the need for human intervention in the process became problematic due to the growing number of services requiring monitoring and the growing number of alerts for them, and the time required for human reaction. Google was early to address the need for automated failover in a reliable fully consistent store during the implementation of their core cluster services, which motivated the creation of Chubby. Later, Apache Zookeeper, etcd and Consul provided open-source implementations of the same idea and were embraced by Internet companies outside of Google. Among these options, etcd offers a few benefits: (a) a modern design around Raft, a newer, more modular consensus algorithm with a lot of support from the engineering community (as opposed to Paxos, the one used in Chubby), (b) client APIs designed around gRPC calls, (c) simplified administration and reduced operational cost, and (d) wide industry adoption due to being a dependency for Kubernetes.
Underlying these implementations is the idea of distributed consensus: an algorithm that allows an odd number of servers to elect a leader automatically, without human intervention. The rest of the servers are "followers" and continue to run without acting on the state, but are ready to take over if the leader becomes unavailable. If an elected leader crashes or gets disconnected during a network outage, the followers that are still available run a new election and quickly promote one of themselves as the new leader. The implementation can advertise the new leader to the system's still available clients in an unambiguous way.
Network Partitions
Consensus solves the potential problem of a system partitioned in two, resulting in "split brain" where database state could diverge: two separate servers where each believes itself to be a master, and disjoint subsets of clients performing modifications on the server they are connected to. This risk is a big part of what motivated the need for human intervention in manual failover, where a common mantra for the operator was to ensure the former master was truly dead before promoting a replica.
In a service based on distributed consensus, there can be only one elected leader at a time. If servers and clients get on different sides of a network partition (where servers and clients in group 1 can reach each other but not servers and clients in group 2, and vice versa), then only one of these two groups has a majority of servers. Either the previous leader ends up on the majority group and manages to keep its elected status, or a new election is run in the majority group, and a new leader surfaces there. Every client and server in the majority group can continue to operate, and every client and server in the minority group knows it can't operate until the partition resolves.
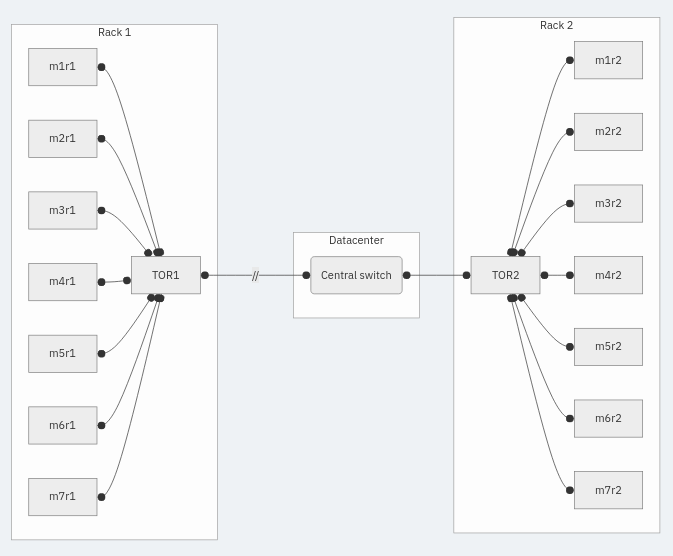
A concrete example helps illustrate the issue. Consider racks in a datacenter that contain some number of machines each, say 7, with all machines in a rack connecting to a top of rack (TOR) switch. In turn, each TOR switch connects to a central switch. Machines on the same rack can talk to each other just by going through the TOR switch. To talk to a machine in a different rack, they need to go through the central switch. Now, imagine deploying a distributed system consisting of several servers and clients to machines in two of these racks. Now, sever the connection to the central switch for the TOR in one rack. This results in a network partition.
Leader Election
The etcd servers in a cluster use consensus to vote and elect a leader. Using an odd number of servers simplifies the process of reaching a majority and defines the minimum number of votes needed to win an election: half plus one, e.g., at least 3 votes in a set of 5 servers. This minimum number of votes also defines the minimum number of still available servers needed for the overall system to continue operation; if fewer servers than that number are available, the system has failed and stops. While this condition could be satisfied with any odd number, in practice the number of servers is always 1, 3, or 5. One server is only good for testing of clients and local development as it doesn't provide any fault tolerance. Three is the minimum number required for fault tolerance, allowing for at most one failure. Five is the preferred number, since it allows for bringing one server down for maintenance while still being able to survive a failure in another server.
While using consensus with seven or more servers is possible in theory, it offers little benefit in terms of increased reliability for a comparatively high cost in latency, complexity, and increased risk due to a lack of testing. Five servers are advised for production systems.
etcd features
Fully consistent, highly available key-value stores like etcd are typically used to support consistent configuration for a distributed system and to implement fault tolerance by relying on the consistent store for availability guarantees.
From a configuration perspective, storing system configuration as values for particular keys in the store provides a strong consistency guarantee on the view of configuration across a cluster: the store guarantees that any reads for configuration that happen after a value has been written correspond to the new value. Full read-after-write consistency in a distributed system is a hard programming problem for which etcd provides a reliable solution. Relational databases do not provide this guarantee: transactions executed from one client do not guarantee immediate visibility from another client. For a in depth explanation, see jepsen.io discussion on consistency models. etcd consistency model in the Jepsen hierarchy is "Strict Serializable"
Consistent stores like etcd also provide the means to subscribe to changes, allowing clients to listen for change notifications rather than having to poll periodically.
The implementation of a distributed system can leverage etcd to get fault tolerance properties without needing to implement sophisticated fault tolerance algorithms. For example, a service cluster can elect a leader simply by issuing a write to a key on the consistent store, conditioned on the previous value being empty. This operation is guaranteed to succeed for only one of the servers that attempt it, and as such, it provides a mechanism for leader election that is simple to program and reason about. Combining this feature with key timeout if a server fails to "heartbeat", plus client subscriptions to the key, these features provide the building blocks for implementing high availability.